Taking a Multi Model Approach to Media Mix Modeling
Why One Model Isn’t Always Enough
If you’ve run a marketing mix model, you’ve probably had this experience: you get a set of ROAS numbers, re-run the model with slightly different settings, and get substantially different results. The channel that looked like your best performer last week now looks average. The one you were about to cut suddenly shows a 5x return.
We ran into this problem on a recent project — 14 paid media channels, 2 years of daily data, and $8.7M in Facebook spend alone. Marketing mix modeling (a statistical method that quantifies each channel’s contribution to revenue) was the right tool for the job. The question was which model to trust.
The Single-Model Problem
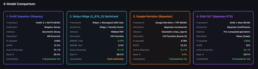
We ran four different statistical engines against the same dataset. Here is what came back for three of our largest channels:
Facebook Awareness ($4.3M total spend): PyMC Shapley estimated a 0.76x ROAS. Orbit returned 0.70x. Robyn Ridge (optimized model 2_674_3) came in at 1.26x. Meridian’s median estimate was 1.28x. Is this channel underwater or profitable? Depends which model you ask.
Google Non-Brand ($353K total spend): PyMC Shapley estimated 14.50x. Orbit returned 10.14x. Robyn Ridge returned 3.23x. Meridian came in at 1.31x. That is a 10x spread on the same channel with the same data.
TikTok ($1.4M total spend): PyMC came in at 4.52x, Orbit at 3.39x, Meridian at 1.72x, and Robyn Ridge at 0.76x. One model says this channel is highly profitable. Another says it is losing money.
Each of these models uses different statistical assumptions, different ways of separating media signal from noise, and different methods for handling channels that tend to move together. Different assumptions produce different answers.
What Went Wrong with Robyn
Before building our own models, we spent months on Meta’s Robyn framework — over 20 model iterations. The results were unstable. Validation accuracy looked strong at 0.93 R-squared, but test accuracy dropped to 0.33 on unseen data.
The root cause was Robyn’s reliance on Nevergrad, an evolutionary optimization algorithm that searches for the best model configuration through trial and error. It is effective at finding a solution, but makes it nearly impossible to diagnose why that solution was selected — or why a different run produces a completely different answer. The underlying ridge regression (a method that penalizes model complexity) also tends to shrink small signals to zero, which explained the missing attribution on lower-spend channels.
The Core Insight
The solution is not to find the single “right” model. It is to run multiple models with fundamentally different statistical assumptions and look for where they agree.
Channels with high cross-model agreement deserve budget confidence. Channels where models disagree need further investigation — or experimental validation through geo-lift or conversion lift studies.